プログラミングの勉強でも登場するキーワード「条件式」。
これはSQLでも重要で、これを勉強しておくことで理解の深さが段違いになるでしょう。
初めて触れる方にとっては最初の登竜門でもあるので、いきなり完璧に習得することは難しいでしょう。
どんなことを勉強することになるかだけを把握して、他の基礎を勉強してから戻って勉強し直すのも一手です。
比較演算、論理演算、条件、条件式、条件分岐、色々な単語が登場する
勉強する環境によって呼び方が多少変わったりします。
当サイトでは、他のプログラミング言語なども含め、汎用的であろう表現を採用します。
普段見慣れない単語ばかりで不安でしょうけど、単語を暗記する必要は無いです。
一つ一つ、しっかり理解を進めましょう。
まずはBOOL型を復習しよう
データ型の紹介で登場したBOOL型です。
TRUEかFALSEの2種類の値を取り扱うデータ型ですが、NULLも含めれば3種類の値を取り扱うとも言えます。
データ型を理解するための記事を設置予定
NULLを理解するための記事を設置予定
「TRUE」は「真」、「YES」の意味で、正しいことを意味しています。
「FALSE」は「偽」、「NO」の意味で、正しくないことを意味しています。
「NULL」は「真偽未定」、「YESかNOか判断できない」の意味だと考えておきましょう。
比較演算を習得するためのXステップ
「条件式」を簡単に言うとBOOL型の値になる式のこと
まずはサンプルクエリを見てみましょう。
SELECT
1 = 1 AS sample_true,
1 = 2 AS sample_false,
1 = CAST(NULL AS INT64) AS sample_null「1 = 1」と「1 = 2」の2つのカラムで計算しています。
初めて条件式に触れる方にとっては、「1 = 2」は間違っているからエラーじゃないか、と想像されるかもしれませんが、SQLで使う「=」(半角イコール)は、数学で使う「=」とは違う意味を持っています。
数学の「=」は、左辺と右辺が等価であることを示すための記号でした。
SQLの「=」は、左辺の値と右辺の値が同じか比較して、同じだったらTRUE、異なっていればFALSEに変換しなさい、という計算指示のための記号となります。
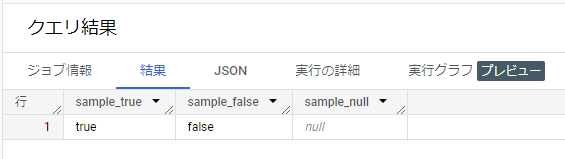
実際に実行した結果を見てみると、「1 = 1」は左辺の値と右辺の値が等しいため、TRUEに変換され出力されています。
一方、「1 = 2」は左辺の値と右辺の値が等しくないため、FALSEに変換され出力されています。
オマケでNULLと比較した場合を用意していますが、左辺の値と右辺の値が等しいか未定となるため、結果もNULLになっています。
この例でいうところの、比較してBOOL値に変換する計算を「比較演算」、比較演算に使った記号「=」を「比較演算子」と言います。
「比較演算」は「条件式」の一部で、「条件式」では必ずしも比較演算を行うわけではないため、表現を分けています。
「比較演算」「比較演算子」という単語は覚えなくて良い
後述の「条件分岐」では、SQLの構文の決まり事で「ここに条件式を入力するように」といった指定があります。
「条件式」、つまり「ここではBOOL型の値が入力されるように」という指定だと言えます。
BOOL型の値を返す代表的な方法として「比較演算」があり、比較演算の使い方を覚えておく必要があります。
なお、「比較演算」や「比較演算子」といった単語は、初心者の勉強時には登場しますが、ビジネスパーソンの実務ではほぼ登場しません。
仕組みや考え方を説明するために登場する単語なので、テスト勉強のように覚えるというよりは、理解し終わった後は忘れて良い単語です。
気軽に読み進めましょう。
色々な比較演算子があると知っておこう
SQLでは「=」(半角イコール)以外にも、色々な比較演算子が用意されています。
難しくて普段使わない比較演算子もあるので、ビジネスパーソンならば、普段からよく使う演算子だけを覚えてしまえば良いでしょう。
数は多いですが、直感的に理解できるものばかりです。
よく使う比較演算子を覚えよう
値の一致を比較したい時は「=」(半角イコール)
前述のとおり、「=」(半角イコール)を使うことで、左辺の値と右辺の値が同じかを比較し、結果をBOOL値で返してくれます。
数学で「=」を使った経験から、数値だけでしか使えないと先入観を持ってしまうことがありますが、SQLでは数値型以外のデータ型でも使えます。
ただし、左辺のデータ型と右辺のデータ型が同じである必要があるので、その点だけご注意ください。
SELECT
"A" = "A" AS sample_true,
"A" = "B" AS sample_false値が一致しないことを比較したい時は「!=」(半角エクスクラメーションマークと半角イコール)か「<>」(半角小なりと半角大なり)
SQLを習熟するほど使う場面は少なくなりますが、「=」の反対、一致しない時はTRUEで一致する時はFALSEを返すように比較することもできます。
「!=」(半角エクスクラメーションマークと半角イコール)、あるいは、「<>」(半角小なりと半角大なり)、どちらを使っても同じで、単に「=」を指定した時のTRUE/FALSEが逆転します。
実際に見かける場面は多いでしょうから、ぜひ覚えておきましょう。
ただ実際は、「このカラムがこの値の時」といった「=」を使う指定の場面より、「このカラムがこの値でない時」といった指定の場面の方が少ないです。
また、後述の「NOT」も使えるようになると、「!=」「<>」で指定する場面も減ります。
習熟後はそれほど使わないでしょうけど、読む時に抵抗感が無い程度には慣れておきましょう。
値の大小を比較したい時は「<」(半角小なり)「>」(半角大なり)
数学では不等式を表す「<」「>」ですが、「=」同様、SQLでは大小関係を比較した結果をBOOL値で返してくれます。
SELECT
1 < 1 AS sample_false,
1 < 2 AS sample_true,
1 < CAST(NULL AS INT64) AS sample_nullこの場合でも数値型以外のデータ型を使えます。
例えば文字列型の大小比較では、辞書の掲載順で考えた時に先に登場する方が小さい、後に登場する方が大きい扱いとなります。
SELECT
"A" < "A" AS sample_false,
"A" < "B" AS sample_true値の以上・以下を比較したい時は「<=」(半角小なりと半角イコール)「>=」(半角大なりと半角イコール)
数学では「≦」「≧」といった記号が使われますが、パソコンの半角文字では同じ記号はありません。
「<=」、「>=」といった書き方になります。
「<」「>」では、左辺の値と右辺の値が等しい時にFALSEになってしまいますが、値が一致した場合もTRUEにしたい時に利用します。
値の範囲で比較したい時は「BETWEEN」「NOT BETWEEN」
前述の比較演算子と比べると、ちょっと特殊な比較演算子に見えるでしょう。
しかし実際は「<=」と「>=」を組み合わせた時と同じ結果になるので、気構える必要はありません。
比較したい値を最初に書いて、次に「BETWEEN」と書きます。
その後ろに、下限の値と上限の値を、「AND」で挟んで書きます。
そうすると、比較したい値が下限と上限の間にあったらTRUE、なければFALSEを返してくれます。
SELECT
0 BETWEEN 1 AND 10 AS sample_0,
1 BETWEEN 1 AND 10 AS sample_1,
5 BETWEEN 1 AND 10 AS sample_5,
10 BETWEEN 1 AND 10 AS sample_10,
11 BETWEEN 1 AND 10 AS sample_11後述の論理演算で登場する「AND」を使うことで、「BETWEEN」と同じことを「<=」「>=」で表現できるようになります。
比較したい値≧下限、かつ、比較したい値≦上限、といった表現に置き換えれるためです。
「NOT BETWEEN」を使う場合は次のようになります。
SELECT
0 NOT BETWEEN 1 AND 10 AS sample_0,
1 NOT BETWEEN 1 AND 10 AS sample_1,
5 NOT BETWEEN 1 AND 10 AS sample_5,
10 NOT BETWEEN 1 AND 10 AS sample_10,
11 NOT BETWEEN 1 AND 10 AS sample_11余談ですが、「BETWEEN」で範囲比較する場面は多いものの、「NOT BETWEEN」で範囲外であることを比較する場面は少ないです。
対象範囲だけ注目したい、対象範囲外は無視したい、そういったデータ抽出場面の方が多いからです。
「NOT BETWEEN」という書き方もできるとだけ理解すればOK、実際に使うのは「BETWEEN」ばかりでしょう。
候補の中から一致するものがあるか比較したい時は「IN」「NOT IN」
いずれかの値と一致する時にTRUE、いずれの値にも一致しなければFALSE、といった条件分岐が求められる場面では、「IN」を使います。
逆に、いずれかの値と一致する時にFALSE、いずれの値にも一致しなければTRUE、としたければ「NOT IN」を使います。
構文としては、調べたい値の後ろに「IN」「NOT IN」と書き、その後ろに「()」(半角括弧)の中に「,」(半角カンマ)区切りで、候補のリストを記載します。
SELECT
"A型" IN ("A型", "B型", "AB型", "O型") AS sample_blood_type_a,
"X型" IN ("A型", "B型", "AB型", "O型") AS sample_blood_type_x後述の「OR」でも表現できる時に、どちらを使ったものか悩む場面も出てくるでしょうが、どちらを採用するかは読み手の読み易さ基準で決めましょう。
読み易さに大差無いようであれば、どちらを使ってもOKです。
「IN」を使う時にNULLが登場すると、思わぬ抽出結果となるケースがあります。
特に、「NOT IN」を使う時にNULLが登場すると、抽出結果が0件になってしまう場合があります。
十分に理解するためにはもう少し勉強が必要ですが、よくある不具合の定番なので、実践段階に入る前にしっかり押さえておきましょう。
WHERE句を紹介する記事を設置予定
よくある不具合(NULL)を紹介する記事を設置予定
「IN」を使う場面としては、クエリを実行した結果を候補リストにしたい場面でしょう。
この使い方ができると、「OR」では表現できないクエリを書くことができます。
ただし、今の段階では勉強しない知識が必要となるので、その時まではスルーしましょう。
WITH句(副問い合わせ、サブクエリ)を習得するための記事を設置予定
値がNULLなのかを比較したい時は「IS NULL」か「IS NOT NULL」
値の一致を比較したい時は「=」でしたが、NULLと比較しようとすると、NULLを評価できずにNULLが返されます。
NULLが未定の値を意味するので、一致するかもしれないし一致しないかもしれない、未定の結果としてNULLになってしまうわけです。
しかし値がNULLなのかを比較したいニーズはあるわけで、NULL比較専用の比較演算子が用意されています。
SELECT
(1 = 1) IS NULL AS sample_true,
(1 = 2) IS NULL AS sample_false,
(1 = CAST(NULL AS INT64)) IS NULL AS sample_null,同様に、「IS NOT NULL」と指定することで、TRUE/FALSEを逆転できます。
SELECT
(1 = 1) IS NOT NULL AS sample_true,
(1 = 2) IS NOT NULL AS sample_false,
(1 = CAST(NULL AS INT64)) IS NOT NULL AS sample_null,WHERE句や集計関数を使う時に、よく利用することになるでしょう。
WHERE句を紹介する記事を設置予定
よく使う集計関数を紹介する記事を設置予定
文字列のパターンを比較したい時は「LIKE」「NOT LIKE」
文字列型専用の比較演算子です。
文字列の一致を比較するなら「=」「!=」「<>」で実現します。
文字列の大小を比較するなら「<」「>」「<=」「>=」「BETWEEN」で実現します。
「LIKE」では、記号「_」(半角アンダーバー)や「%」(半角パーセント)を使うことで、文字列パターンでの比較ができます。
SELECT
"文字列パターンを比較します。" LIKE "文字列パターン_比較します。" AS sample_1, -- 「を」の1文字分の違いがあるのでTRUEになる。
"文字列パターンを比較します。" LIKE "文字列パターン_します。" AS sample_2, -- これは3文字分の違いがあるのでFALSEになる。
"文字列パターンを比較します。" LIKE "文字列パターン___します。" AS sample_3, -- これは3文字分の違いがあるのでTRUEになる。
"文字列パターンを比較します。" LIKE "文字列%比較します。" AS sample_4, -- 5文字分の違いを「%」で比較しているのでTRUEになる。
"文字列パターンを比較します。" LIKE "文字列パターンを%比較します。" AS sample_5, -- 0文字分の違いを「%」で比較しているのでTRUEになる。
"文字列パターンを比較します。" LIKE "%パターン%" AS sample_6, -- 「パターン」という文字列が含まれる場合TRUEになる指定。よく使う書き方。
"文字列パターンを比較します。" LIKE "文字列%" AS sample_7, -- 「文字列」という文字列で始まる場合TRUEになる指定。よく使う書き方。
"文字列パターンを比較します。" LIKE "%比較します。" AS sample_8, -- 「比較します。」という文字列で終わる場合TRUEになる指定。よく使う書き方。
"「_」や「%」を含む文字列パターンを比較します。" LIKE "「\\_」や「\\%」を含む%" AS sample_9 -- 比較したい文字列に「_」や「%」が含まれている場合の書き方。「_」(半角アンダーバー)は何らかの1文字を表し、「%」(半角パーセント)は何らかの文字列(0文字を含む長さ不定の文字列)を表します。
実際によく使うのは「%」の方で、前述の例の中でも、「sample_6」「sample_7」「sample_8」の書き方によく遭遇するでしょう。
余談ですが、「LIKE」でパターンに一致することを計算する場面は多いものの、「NOT LIKE」でパターンに一致しないことを計算する場面は少ないです。
パターンに一致する時に注目したい、パターンに一致しない時は無視したい、そういったデータ抽出場面の傾向があるからです。
「NOT LIKE」という書き方もできるとだけ理解すればOK、実際に使うのは「LIKE」ばかりでしょう。
前述の例の中の「sample_9」は「エスケープ処理」と呼ばれる前処理で、比較パターンを表現するための文字「_」(半角アンダーバー)や「%」(半角パーセント)を、何らかの文字として比較するのではなく、文字の通り比較したい場合に使う書き方で、「\」(半角バックスラッシュ)を前に2つ書きます。
「\」(半角バックスラッシュ)は、ご利用のキーボードによっては半角円マークになっています。
このような比較をしたいケースは稀でしょうが、遭遇した時に対応できるように、引き出しの一つとして覚えておきましょう。
なお、もっと複雑な文字列パターン比較の方法として、正規表現を使うケースがあります。
これを使いこなすのは初心者には厳しいので、今はスルーしておきましょう。
正規表現を紹介する記事を設置予定
論理演算(AND、OR、NOT)を使いこなして多彩な条件を制御できるようになろう
比較演算の話が終わって、次は論理演算の話です。
高校数学を思い出した時に登場する、「かつ」や「または」の話です。
BOOL型の値を組み合わせることで、BOOL型の値を返します。
よく使う論理演算子は3種類
「AND」は「かつ」を示す
いわゆる「かつ」を示す条件で、「AND」の左側のBOOL型の値、「AND」の右側のBOOL型の値、その両方がTRUEである場合にTRUE、いずれかにFALSEが含まれていればFALSEを返します。
SELECT
TRUE AND TRUE AS sample_tt,
TRUE AND FALSE AS sample_tf,
FALSE AND TRUE AS sample_ft,
FALSE AND FALSE AS sample_ffなお、「BETWEEN」の構文で使う「AND」とは別物なので、区別して覚えるようにしましょう。
「OR」は「または」を示す
いわゆる「または」を示す条件で、「OR」の左側のBOOL型の値、「OR」の右側のBOOL型の値、そのいずれかがTRUEである場合にTRUE、両方にFALSEが含まれていればFALSEを返します。
SELECT
TRUE OR TRUE AS sample_tt,
TRUE OR FALSE AS sample_tf,
FALSE OR TRUE AS sample_ft,
FALSE OR FALSE AS sample_ff「NOT」はTRUE/FALSEの反転を示す
TRUEであればFALSE、FALSEであればTRUEを返します。
SELECT
NOT (TRUE) AS sample_not_true,
NOT (FALSE) AS sample_not_false「NOT BETWEEN」「NOT IN」「IS NOT NULL」「NOT LIKE」でも「NOT」が登場するので最初は紛らわしいかもしれませんが、使っていく内に慣れる範囲でしょう。
「()」(半角括弧)は省略できますが、慣れない内は必ず「()」(半角括弧)を書くようにして、その中にはBOOL型の値が入るようになっていれば間違えないです。
ORの計算順序に注意
「AND」と「OR」では、「AND」が先に計算されます。
「OR」を先に計算させたい場合には、数学同様、「()」(半角括弧)で先に計算させます。
SELECT
TRUE OR FALSE AND FALSE,
TRUE OR (FALSE AND FALSE),
(TRUE OR FALSE) AND FALSEこれに注意しておかないと、思わぬ計算順序になってしまい、想定外の抽出結果になるので注意しましょう。
間違えないためには、「OR」を書いた時に、明示的に「()」(半角括弧)を書いて、計算順序を指定することです。
なお、「AND」が先に計算されるからと「()」(半角括弧)を省略してしまうと、読み手側が「もしかして括弧の書き洩らしじゃないか?」と不安を招いてしまうので、省略しないことをオススメします。
NULLを扱う時の注意
「IN」「NOT IN」の項目でも触れましたが、条件によっては不具合を招きます。
「NOT」でNULLを指定すると、NULLが返されます。
SELECT
NOT (TRUE) AS sample_not_true,
NOT (FALSE) AS sample_not_false,
NOT (CAST(NULL AS BOOL)) AS sample_not_null繰り返しになりますが、よくある不具合の代表例なので、しっかり覚えておきましょう。
よくある不具合(NULL)を紹介する記事を設置予定
条件式はWHERE句で多用する
さて、勉強し始めの段階で、ここまで苦労して条件式を勉強するのには理由があります。
次に勉強する「WHERE」句で多用するためです。
「AND」「OR」「NOT」のいずれもよく使いますが、特に「AND」を頻繁に使います。
クエリを書けば書くほど、嫌でも多用することになるでしょう。
WHERE句を紹介する記事を設置予定
条件分岐とは
ここまで比較演算子や論理演算子を勉強してきましたが、本記事の最後に、「条件分岐」も覚えておきましょう。
単語から想像できるでしょうが、この時はこっち、そうじゃない時はこっち、といった、条件に沿って違う結果を導くことができます。
BigQueryで使える条件分岐は5種類
CASE構文
最も多彩な条件を表現できる分、初めて勉強する時に苦労する条件分岐です。
先に難しい条件分岐を勉強してしまいましょう。
CASE構文の書き方その1
「CASE」の後ろに、比較したい値を書きます。
その後ろに、「WHEN」、「CASE」で指定した値と比較したい値、「THEN」、比較した結果一致した場合に使いたい値、これら4つの組み合わせを、指定したい条件の数だけ指定します。
いずれの条件にも合致しない場合を指定したい場合、「ELSE」、いずれの条件にも合致しない場合に使いたい値、これら2つの組み合わせを一組指定します。
最後に「END」と書いて、CASE構文の終わりを指定します。
SELECT
CASE "「WHEN」の3つ目"
WHEN "「WHEN」の1つ目" THEN "1つ目の条件に合致しました。"
WHEN "「WHEN」の2つ目" THEN "2つ目の条件に合致しました。"
WHEN "「WHEN」の3つ目" THEN "3つ目の条件に合致しました。" -- 「CASE」で指定した値が合致するので、この値が使われる。
WHEN "「WHEN」の4つ目" THEN "4つ目の条件に合致しました。"
ELSE "いずれの条件にも合致しません。"
END「ELSE」の指定は省略可能で、「ELSE」が無いCASE構文で「WHEN」のいずれにも合致しなかった場合、NULLが返されます。
SELECT
CASE "「WHEN」のXXつ目"
WHEN "「WHEN」の1つ目" THEN "1つ目の条件に合致しました。"
WHEN "「WHEN」の2つ目" THEN "2つ目の条件に合致しました。"
WHEN "「WHEN」の3つ目" THEN "3つ目の条件に合致しました。"
WHEN "「WHEN」の4つ目" THEN "4つ目の条件に合致しました。"
END -- いずれの値にも合致しないため、NULLが返される。とはいえ、読み手が「ELSEの指定漏れかも?」と不安になるでしょうから、明示的に「ELSE NULL」と指定してあげた方が親切でしょう。
SELECT
CASE "「WHEN」のXXつ目"
WHEN "「WHEN」の1つ目" THEN "1つ目の条件に合致しました。"
WHEN "「WHEN」の2つ目" THEN "2つ目の条件に合致しました。"
WHEN "「WHEN」の3つ目" THEN "3つ目の条件に合致しました。"
WHEN "「WHEN」の4つ目" THEN "4つ目の条件に合致しました。"
ELSE NULL
ENDもう一つ注意しておくこととして、「WHEN」の指定順序です。
前から順番に評価され、最初に合致した時のTHENが使われます。
指定する順序にも気を配りましょう。
SELECT
CASE "「WHEN」の3つ目"
WHEN "「WHEN」の1つ目" THEN "1つ目の条件に合致しました。"
WHEN "「WHEN」の2つ目" THEN "2つ目の条件に合致しました。"
WHEN "「WHEN」の3つ目" THEN "3つ目(その1)の条件に合致しました。" -- 「CASE」で指定した値が合致し、先に評価されるので、この値が使われる。
WHEN "「WHEN」の3つ目" THEN "3つ目(その2)の条件に合致しました。" -- 「CASE」で指定した値が合致するが、後に評価されるため、この値は使われない。
WHEN "「WHEN」の4つ目" THEN "4つ目の条件に合致しました。"
ELSE "いずれの条件にも合致しません。"
ENDCASE構文の書き方その2
「CASE構文の書き方その1」の応用として、次の書き方を覚えておきましょう。
SELECT
CASE TRUE
WHEN ("「WHEN」の1つ目" = "「WHEN」の3つ目") THEN "1つ目の条件に合致しました。"
WHEN ("「WHEN」の2つ目" = "「WHEN」の3つ目") THEN "2つ目の条件に合致しました。"
WHEN ("「WHEN」の3つ目" = "「WHEN」の3つ目") THEN "3つ目の条件に合致しました。" -- 「CASE」で指定した値が合致するので、この値が使われる。
WHEN ("「WHEN」の4つ目" = "「WHEN」の3つ目") THEN "4つ目の条件に合致しました。"
ELSE "いずれの条件にも合致しません。"
END「CASE」の後ろにBOOL型の値としてTRUEを指定することで、「WHEN」の一つ一つで条件式を指定しています。
最初に条件式がTRUEとなった時の、「THEN」で指定した値が使われるようになります。
CASE構文の書き方その3
「CASE構文の書き方その2」で指定した「CASE TRUE」は、「TRUE」を省略できます。
この書き方を使う人は多いので、定型句として覚えておきましょう。
SELECT
CASE
WHEN ("「WHEN」の1つ目" = "「WHEN」の3つ目") THEN "1つ目の条件に合致しました。"
WHEN ("「WHEN」の2つ目" = "「WHEN」の3つ目") THEN "2つ目の条件に合致しました。"
WHEN ("「WHEN」の3つ目" = "「WHEN」の3つ目") THEN "3つ目の条件に合致しました。" -- 「WHEN」で指定した条件式の値が最初にTRUEになるので、この値が使われる。
WHEN ("「WHEN」の4つ目" = "「WHEN」の3つ目") THEN "4つ目の条件に合致しました。"
ELSE "いずれの条件にも合致しません。"
ENDCASE構文を使う時の注意点
CASEを使ったクエリを書く時は、条件の書き洩らしがそのままクエリの不具合に繋がります。
「他にもこんな条件があるのではないか」と、想定されるパターンを念入りに検討する必要があるため、注意しながら使いましょう。
IF関数
Excelなどの表計算ソフトでもおなじみの条件分岐です。
「IF」の後ろに「()」(半角括弧)を書いて、その中に「,」(半角カンマ)区切りで3つのパラメータを指定します。
1つ目のパラメータには条件式を指定します。
2つ目のパラメータには、1つ目で指定した条件式がTRUEだった場合の値を指定します。
3つ目のパラメータには、1つ目で指定した条件式がTRUEではなかった場合の値を指定します。
2つ目と3つ目のデータ型は同じである必要があります。
SELECT
IF(TRUE, "これはTRUEです。", "これはTRUEではありません。")IFNULL関数
値がNULLだったら別の値を使う時の、専用の条件分岐です。
使い道が少なそうに思うかもしれませんが、「もしNULLだったら」という条件分岐を使う場面は非常に多く、都度CASEやIFで書くとタイピング量が多くなります。
IFNULLを使うとタイピング量も少なく、読み手にとっても「「もしNULLだったら」の条件分岐にしたいんだな」と簡単に伝わります。
筆者おすすめの条件分岐関数です。
「IFNULL」の後ろに「()」(半角括弧)を書いて、その中に「,」(半角カンマ)区切りで2つのパラメータを指定します。
1つ目のパラメータには、値がNULLじゃなければ使いたい値を指定します。
2つ目のパラメータには、1つ目の値がNULLだった場合に使う値を指定します。
SELECT
IFNULL("1つ目のパラメータがNULLじゃなかった場合の値です。", "1つ目のパラメータがNULLだった場合の値です。"),
IFNULL(CAST(NULL AS STRING), "1つ目のパラメータがNULLだった場合の値です。")COALESCE関数
読み方をカタカナに直すと「コウアレス」となります。
IFNULL関数の拡張版のような関数で、2つのパラメータだけでなく、3つ以上のパラメータを指定できます。
使う場面は稀ですが、使いこなせるとクエリが読み易くなる場合があります。
「COALESCE」の後ろに「()」(半角括弧)を書いて、その中に「,」(半角カンマ)区切りで複数のパラメータを指定します。
3個でも4個でも5個でも大丈夫で、環境次第ですが、100個以上指定することもできます。
(BigQueryの関数リファレンスでは個数上限の記載が無いようです。)
SELECT
COALESCE("1つ目のパラメータがNULLじゃなかった場合の値です。", "1つ目のパラメータがNULLだった場合の値です。"),
COALESCE(CAST(NULL AS STRING), "1つ目のパラメータがNULLだった場合の値です。"),
COALESCE(CAST(NULL AS STRING), CAST(NULL AS STRING), "1つ目と2つ目のパラメータがNULLだった場合の値です。"),
COALESCE(CAST(NULL AS STRING), CAST(NULL AS STRING), CAST(NULL AS STRING), "1つ目と2つ目と3つ目のパラメータがNULLだった場合の値です。")NULLIF関数
ほぼ使いません。
CASEしか使わないようにしているチームも多い
条件分岐の書き方を5種類紹介しましたが、最も汎用性があるCASE構文だけ使えれば、他4種類を使わず、条件分岐を表現することができます。
そのため、「CASE以外の条件分岐を使わないように」といったルールにしているチームも多いです。
チームの文化に従い、適切に対応できるようになっておきましょう。
ちなみに筆者は、CASE以外の条件分岐を積極的に使うことをおすすめしています。
まず、条件分岐自体がシンプルになり読みやすくなるメリットがあります。
次に、「IF」や「IFNULL」と指定されたところを見るだけで、クエリを書いた人の意図を読めるようになり、意図にそぐわない書き方を見かけた時に不具合を検知できる場合があります。
「IF」や「IFNULL」を積極的に使うルールとしているチームで、クエリの違和感から不具合を検知できるケースを紹介します。
下記のクエリは、信号機の色から信号の意味を表すようなクエリになっています。
WITH
traffic_light AS (
SELECT "red" AS light_color
),
SELECT
CASE WHEN light_color = "red" THEN "止まれ" ELSE "進め" AS traffic_light_meaning
FROM traffic_lightIFで表現できそうな条件分岐が、CASEで表現されています。
このクエリを書いた人は、「IFで表現できないからCASEを使おう」と考えていたのであれば、WHEN、THENが1個しか無いのは不自然です。
IFで書くことができることに気付かなかったか、CASEで書いている途中で条件の抜け漏れがあったかのいずれかでしょう。
少なくとも、クエリを書いた人が見直し不十分であることは確かだと言え、不具合検知に役立ちます。
SELECT句で条件式を使うテクニックも大事
これまで掲載したサンプルでは、SELECT句の中で条件式を掲載してきました。
条件式を使う場面としては、WHERE句や条件分岐がメジャーでしょう。
チームによっては、それ以外で条件式を使わない場合もあります。
しかし筆者としては、積極的にSELECT句で使って、そのメリットを享受することをおすすめします。
クエリ自体が読みやすくなり、不具合も検知しやすくなります。
デバッグの重要性を説明するための記事を設置予定
可読性・保守性を説明するための記事を設置予定
振り返り
お疲れさまでした。
勉強する量が多く、苦労したでしょう。
本記事で勉強した内容を理解していれば、次の「WHERE」句は楽勝です。
WHERE句を紹介する記事を設置予定